Não é de hoje que leitores do site pedem para que eu escreva sobre o Dapper, micro-ORM que tem a fama de ser extremamente performático e simples de utilizar. Eu relutei para escrever sobre essa biblioteca, principalmente porque até hoje eu não tive nenhuma experiência com ela, e eu só costumo escrever sobre alguma coisa quando eu tenho certeza do que eu estou falando (apesar que às vezes eu acabo falando algumas besteiras também – faz parte).
Porém, uma vez que o Dapper foi um dos tópicos mais votados na minha última pesquisa de temas para próximos artigos, aí não teve jeito. Resolvi me aprofundar nos estudos sobre essa biblioteca e, no artigo de hoje, vou apresentar para você uma “Introdução ao Dapper“, tomando como base os resultados dos meus aprendizados. Você se interessa por esse tema? Então vamos lá!

Disclaimer
Como mencionei na introdução do artigo, até a semana passada (que foi quando eu parei para estudar “de verdade” do Dapper), eu não tinha tido nenhuma experiência com ele. Eu apenas tinha lido “por cima” alguns artigos e assistido rapidamente alguns vídeos sobre essa biblioteca. Dessa forma, se eu acabar falando alguma besteira neste artigo, por favor, me corrija nos comentários, OK?
Aproveitando essa seção de “disclaimer“, quero deixar aqui uma lista com os recursos que eu utilizei para aprender o conteúdo que ensinarei neste artigo. A maioria deles foi elaborado pelo meu amigo Renato Groffe, que é Microsoft MVP e conhecido por ser uma “máquina de produzir conteúdo“, hehehe. Aqui vão os links:
Dapper: exemplos em .NET Core 2.0 e ASP.NET Core 2.0 (link)
Coletânea de artigos, exemplos e vídeos com participação do Renato Groffe onde ele aborda a utilização do Dapper. Recomendo que você dê uma olhada nos exemplos postados no GitHub dele, além de dar uma lida nos artigos mencionados, como, por exemplo, este artigo mostrando o conceito de relacionamentos no Dapper.
ORMs em .NET: Entity Framework, NHibernate e Dapper (link)
Hangout com participação do André Secco, Luiz Carlos Faria e Renato Groffe mostrando as particularidades do Entity Framework, NHibernate e Dapper. Recomendo que você assista para conseguir ter uma melhor base na hora de escolher um ORM ou micro-ORM (ou talvez até mesmo ADO.NET puro) para o seu projeto.
Acesso a dados em .NET Core: Entity Framework Core e Dapper (link)
Dos links que eu estou listando aqui, esse é o mais novo, que foi uma apresentação do André Secco na versão local do DotNetConf. Nesse vídeo o André Secco mostra a utilização do Entity Framework e do Dapper, bem como um cenário híbrido utilizando as duas tecnologias ao mesmo tempo (Entity Framework para CRUD e Dapper para consultas).
Entendendo o problema
Antes de mostrar a utilização do Dapper, é importante entendermos o problema que ele se propõe a resolver. Praticamente toda aplicação que nós construímos terá algum tipo de armazenamento de informações no banco de dados. Normalmente, a estrutura do banco de dados refletirá de certa forma a estrutura de classes da nossa aplicação (ou vice-versa).
Quando implementamos a interface com o banco de dados no nosso projeto .NET, nós temos basicamente três opções: ou trabalhamos com ADO.NET puro (fazendo todas as consultas “na mão“), ou utilizamos um ORM (como Entity Framework ou NHibernate) ou um micro-ORM (como o Dapper). Os ORMs atuam como uma camada entre as classes da aplicação e o ADO.NET, de maneira que nós não precisemos praticamente escrever nenhuma sentença SQL para nos comunicarmos com o banco. Eles possibilitam o mapeamento das classes do nosso projeto com as tabelas no banco de dados (daí o nome ORM = “Object-Relational Mapping“).
Quanto mais produtiva é a abordagem que nós escolhemos (ORMs), menos performática ela será. Por consequência, se precisarmos de uma performance absurda na nossa aplicação, nós provavelmente não poderemos trabalhar com ORMs, mas sim, com ADO.NET puro.
A ideia dos micro-ORMs é justamente dar uma opção intermediária entre produtividade e performance. Eles trazem parte das funcionalidades de mapeamento objeto-relacional dos ORMs, mas sem implementar a cacetada de funcionalidades (muitas vezes pouco utilizadas) que acabam os deixando mais lentos.
Projeto de exemplo sem Dapper
Para estudarmos a utilização do Dapper no acesso a dados, vamos trabalhar com um projeto do tipo “Console Application“. Essa aplicação criará registros em uma tabela chamada “Pessoa” dentro de um banco SQLite. Para focarmos no que é importante, vamos manter a estrutura dessa tabela extremamente simples, contendo somente os campos “Id” (chave primária, auto-incremento), “Nome” e “Sobrenome“:
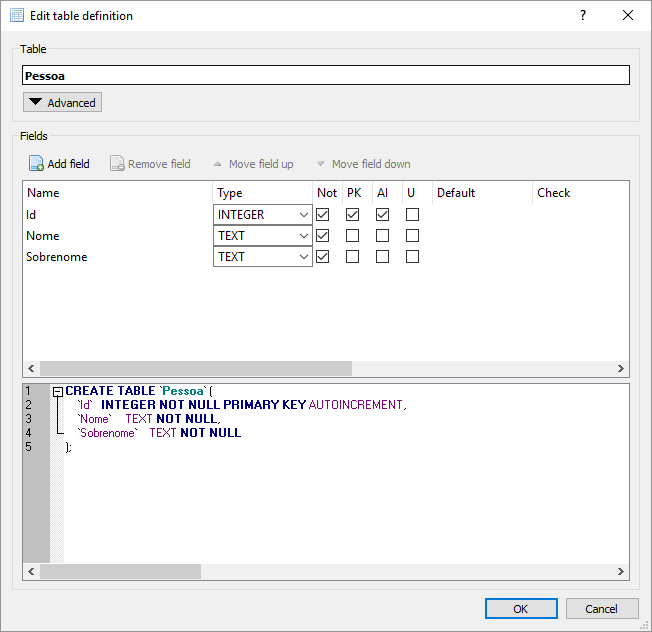
Nota: baixe o banco de dados vazio (que tem somente essa tabela criada) através deste link e coloque-o dentro da pasta bin/debug do seu projeto.
Dentro do nosso projeto, vamos adicionar a classe correspondente, que também terá o nome de “Pessoa“:
// C#
public class Pessoa
{
public int Id { get; set; }
public string Nome { get; set; }
public string Sobrenome { get; set; }
}
' VB.NET
Public Class Pessoa
Public Property Id As Integer
Public Property Nome As String
Public Property Sobrenome As String
End Class
Em seguida, vamos adicionar uma referência para a biblioteca de acesso a dados do SQLite através do NuGet:
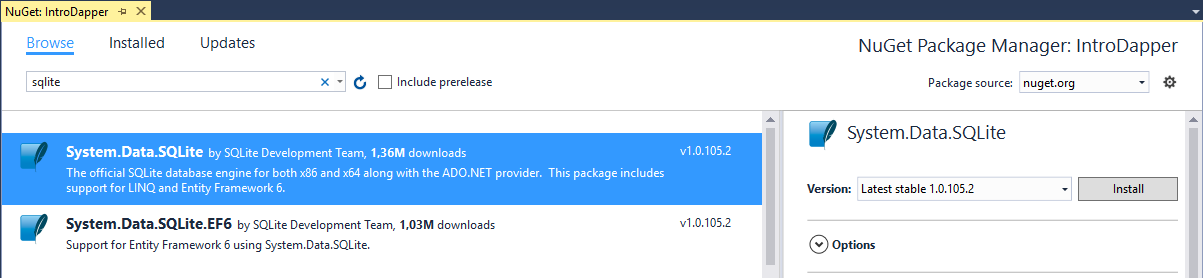
Nota: uns tempos atrás eu escrevi um artigo completo mostrando como trabalhar com o SQLite utilizando ADO.NET puro e Entity Framework. Se você não entender o que estou fazendo aqui neste artigo até agora, sugiro que você dê uma olhada primeiro no artigo básico sobre SQLite.
Como mencionei acima, essa aplicação basicamente fará o cadastro de novas pessoas nessa tabela, bem como a listagem das pessoas que estão cadastradas. Dito isso, o código do método “main” deverá ter esta estrutura:
// C#
static void Main(string[] args)
{
string nome = string.Empty;
do
{
Console.WriteLine("Digite o nome:");
nome = Console.ReadLine();
if (!string.IsNullOrWhiteSpace(nome))
{
Console.WriteLine("Digite o sobrenome:");
var sobrenome = Console.ReadLine();
if (!string.IsNullOrWhiteSpace(sobrenome))
{
var pessoa = new Pessoa()
{
Nome = nome,
Sobrenome = sobrenome
};
CadastrarPessoaNoBanco(pessoa);
}
}
ListarPessoas();
}
while (!string.IsNullOrWhiteSpace(nome));
Console.ReadLine();
}
' VB.NET
Sub Main()
Dim Nome As String = String.Empty
Do
Console.WriteLine("Digite o nome:")
Nome = Console.ReadLine()
If Not String.IsNullOrWhiteSpace(Nome) Then
Console.WriteLine("Digite o sobrenome:")
Dim Sobrenome = Console.ReadLine()
If Not String.IsNullOrWhiteSpace(Sobrenome) Then
Dim Pessoa = New Pessoa() With
{
.Nome = Nome,
.Sobrenome = Sobrenome
}
CadastrarPessoaNoBanco(Pessoa)
End If
End If
ListarPessoas()
Loop While Not String.IsNullOrWhiteSpace(Nome)
Console.ReadLine()
End Sub
Observe que nós estamos pedindo as informações de nome e sobrenome para o usuário e, em seguida, criamos uma instância da classe “Pessoa” que será passada para o método “CadastrarPessoaNoBanco“. Por fim, nós chamamos o método “ListarPessoas“, que carregará os dados da tabela “Pessoa” em memória e imprimirá o resultado na tela. Todo esse processo será executado enquanto o usuário informar um nome que seja diferente de “vazio“.
O código do método “CadastrarPessoaNoBanco” com a utilização do ADO.NET puro é muito simples. Instanciamos uma conexão com o banco, abrimos essa conexão, criamos um comando com a sentença SQL “INSERT” e passamos os valores através de parâmetros do ADO.NET. Por fim, chamamos o método “ExecuteNonQuery” para persistirmos as informações no banco:
// C#
private static void CadastrarPessoaNoBanco(Pessoa pessoa)
{
using (var conn = new System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;"))
{
conn.Open();
if (conn.State == System.Data.ConnectionState.Open)
{
using (var comm = new System.Data.SQLite.SQLiteCommand("INSERT INTO Pessoa (Nome, Sobrenome) VALUES (@Nome, @Sobrenome)", conn))
{
comm.Parameters.AddWithValue("Nome", pessoa.Nome);
comm.Parameters.AddWithValue("Sobrenome", pessoa.Sobrenome);
comm.ExecuteNonQuery();
}
}
}
}
' VB.NET
Private Sub CadastrarPessoaNoBanco(pessoa As Pessoa)
Using Conn = New System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;")
Conn.Open()
If Conn.State = System.Data.ConnectionState.Open Then
Using Comm = New System.Data.SQLite.SQLiteCommand("INSERT INTO Pessoa (Nome, Sobrenome) VALUES (@Nome, @Sobrenome)", Conn)
Comm.Parameters.AddWithValue("Nome", pessoa.Nome)
Comm.Parameters.AddWithValue("Sobrenome", pessoa.Sobrenome)
Comm.ExecuteNonQuery()
End Using
End If
End Using
End Sub
Nota: se você não utiliza a funcionalidade de parâmetros do ADO.NET, mas sim concatena os valores direto na sentença SQL, pare agora mesmo e leia este outro artigo! Sério, é super importante!
Por sua vez, o código do método “ListarPessoas” também é bem simples. Nós executaremos um “SELECT” no banco pegando todos os registros da tabela “Pessoa” (utilizando DataReader) e colocaremos o resultado em uma lista. Em seguida, nós percorremos essa lista e imprimimos as informações das pessoas na tela:
// C#
private static void ListarPessoas()
{
Console.WriteLine("======= Listagem de pessoas =======");
var pessoas = CarregarPessoasDoBanco();
foreach (var pessoa in pessoas)
{
Console.WriteLine("Id: {0}, Nome: {1}, Sobrenome: {2}", pessoa.Id, pessoa.Nome, pessoa.Sobrenome);
}
Console.WriteLine("===================================");
}
private static IEnumerable<Pessoa> CarregarPessoasDoBanco()
{
var pessoas = new List<Pessoa>();
using (var conn = new System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;"))
{
conn.Open();
if (conn.State == System.Data.ConnectionState.Open)
{
using (var comm = new System.Data.SQLite.SQLiteCommand("SELECT * FROM Pessoa", conn))
using (var reader = comm.ExecuteReader())
{
while (reader.Read())
{
var pessoa = new Pessoa();
pessoa.Id = Convert.ToInt32(reader["Id"]);
pessoa.Nome = reader["Nome"].ToString();
pessoa.Sobrenome = reader["Sobrenome"].ToString();
pessoas.Add(pessoa);
}
}
}
}
return pessoas;
}
' VB.NET
Private Sub ListarPessoas()
Console.WriteLine("======= Listagem de pessoas =======")
Dim Pessoas = CarregarPessoasDoBanco()
For Each Pessoa In Pessoas
Console.WriteLine("Id: {0}, Nome: {1}, Sobrenome: {2}", Pessoa.Id, Pessoa.Nome, Pessoa.Sobrenome)
Next
Console.WriteLine("===================================")
End Sub
Private Function CarregarPessoasDoBanco() As IEnumerable(Of Pessoa)
Dim Pessoas = New List(Of Pessoa)()
Using Conn = New System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;")
Conn.Open()
If Conn.State = System.Data.ConnectionState.Open Then
Using Comm = New System.Data.SQLite.SQLiteCommand("SELECT * FROM Pessoa", Conn)
Using Reader = Comm.ExecuteReader()
While Reader.Read()
Dim Pessoa = New Pessoa()
Pessoa.Id = Convert.ToInt32(Reader("Id"))
Pessoa.Nome = Reader("Nome").ToString()
Pessoa.Sobrenome = Reader("Sobrenome").ToString()
Pessoas.Add(Pessoa)
End While
End Using
End Using
End If
End Using
Return Pessoas
End Function
Pronto! Esse é o código da nossa aplicação utilizando ADO.NET puro, sem Dapper, sem Entity Framework, o mais simples e performático possível. Execute a aplicação, crie algumas pessoas e veja o resultado:
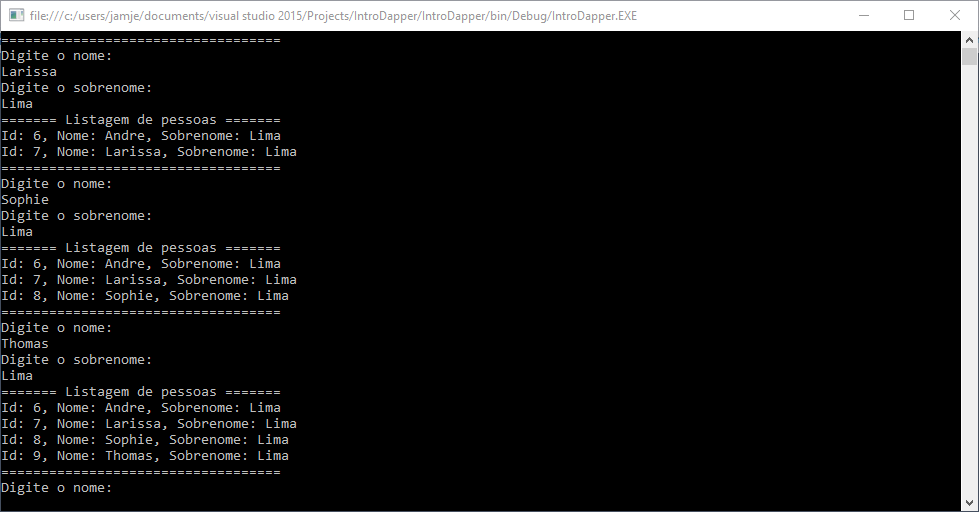
Qual é exatamente o problema dessa implementação? Como o Dapper poderia deixar esse nosso código mais simples? Isso é o que veremos agora.
Instalando o Dapper
Primeiramente, a instalação do Dapper é muito tranquila. Basta adicionarmos a referência através do NuGet:
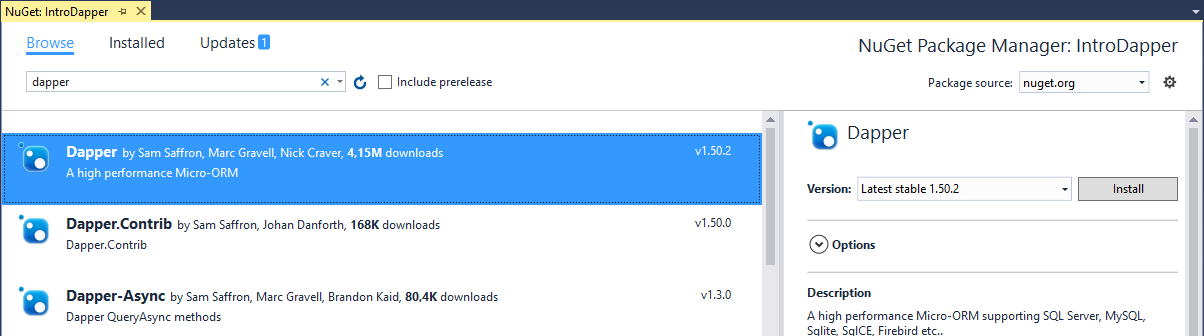
Feito isso, para termos acesso aos métodos de extensão disponibilizados pelo Dapper, nós precisamos adicionar uma cláusula “using Dapper;” (ou “Imports Dapper” no VB.NET) no cabeçalho do arquivo onde faremos a sua utilização (no nosso caso, o arquivo “Program.cs” ou “Module1.vb“). Não esqueça desse passo, caso contrário você não conseguirá encontrar os métodos especiais do Dapper.
Mapeando resultados de uma consulta com o Dapper
O Dapper pode nos ajudar no mapeamento dos resultados do banco em instâncias das nossas classes de modelo. Ou seja, ao invés de pegarmos as informações através de um DataReader e criarmos manualmente as instâncias da classe “Pessoa“, nós podemos utilizar o Dapper para fazer esse trabalho “sujo“.
Veja só como é que fica o novo código do método “CarregarPessoasDoBanco” com a utilização do Dapper:
// C#
private static IEnumerable<Pessoa> CarregarPessoasDoBanco()
{
IEnumerable<Pessoa> pessoas = null;
using (var conn = new System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;"))
{
conn.Open();
if (conn.State == System.Data.ConnectionState.Open)
{
pessoas = conn.Query<Pessoa>("SELECT * FROM Pessoa");
}
}
return pessoas;
}
' VB.NET
Private Function CarregarPessoasDoBanco() As IEnumerable(Of Pessoa)
Dim Pessoas As IEnumerable(Of Pessoa) = Nothing
Using Conn = New System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;")
Conn.Open()
If Conn.State = System.Data.ConnectionState.Open Then
Pessoas = Conn.Query(Of Pessoa)("SELECT * FROM Pessoa")
End If
End Using
Return Pessoas
End Function
Observe que agora estamos utilizando o método “Query” do Dapper. Esse método recebe o tipo de dados que deverá ser gerado (no nosso caso “Pessoa“) e a sentença que será utilizada para preencher os resultados. Por trás dos panos, o Dapper executa aquela sentença, cria instâncias do tipo especificado e retorna um “IEnumerable” daquele tipo. Bem mais simples, não é mesmo?
Executando comandos parametrizados com o Dapper
Uma outra funcionalidade bem bacana que o Dapper disponibiliza são as consultas parametrizadas com objetos anônimos. Lembra o código do método “CadastrarPessoaNoBanco” que vimos ali em cima? Naquele código nós tivemos que criar um comando, adicionar cada um dos parâmetros e, por fim, chamamos o método “ExecuteNonQuery” para que o comando fosse executado. Com o Dapper, esse código fica muito mais enxuto:
// C#
private static void CadastrarPessoaNoBanco(Pessoa pessoa)
{
using (var conn = new System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;"))
{
conn.Open();
if (conn.State == System.Data.ConnectionState.Open)
{
conn.Execute(
"INSERT INTO Pessoa (Nome, Sobrenome) VALUES (@Nome, @Sobrenome)",
new { Nome = pessoa.Nome, Sobrenome = pessoa.Sobrenome });
}
}
}
' VB.NET
Private Sub CadastrarPessoaNoBanco(pessoa As Pessoa)
Using Conn = New System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;")
Conn.Open()
If Conn.State = System.Data.ConnectionState.Open Then
Conn.Execute("INSERT INTO Pessoa (Nome, Sobrenome) VALUES (@Nome, @Sobrenome)", New With
{
.Nome = pessoa.Nome,
.Sobrenome = pessoa.Sobrenome
})
End If
End Using
End Sub
Como você pode perceber, o método “Execute” implementado pelo Dapper possibilita que nós passemos os parâmetros através de um objeto anônimo (que são aqueles objetos criados com a palavra reservada “new“). Ou seja, nós informamos os nomes dos parâmetros na sentença SQL (precedidos de arroba) e depois passamos os valores através de um objeto anônimo. Muito bacana!
Implementando CRUD com Dapper.Contrib
As melhorias proporcionadas pelo Dapper que vimos até agora já dão uma bela ajudada na hora de carregarmos informações do banco com ADO.NET puro. Porém, dá para ficar ainda melhor! Com uma extensão do Dapper chamada “Dapper.Contrib“, as nossas operações de criação, alteração e deleção de registros ficarão mais fáceis ainda.
Primeiramente, vamos adicionar a referência para essa biblioteca através do NuGet:
Em seguida, precisamos adicionar uma cláusula “using Dapper.Contrib.Extensions;” (ou “Imports Dapper.Contrib.Extensions” no VB.NET) no cabeçalho do arquivo onde queremos acessar as suas funcionalidades (no nosso caso, o arquivo “Program.cs” ou “Module1.vb“).
Feito isso, teremos acesso aos métodos de extensão do “Dapper.Contrib“, que basicamente nos ajudam a implementar as funcionalidades de CRUD mais facilmente (os principais métodos são “Get“, “GetAll“, “Insert“, “Update“, “Delete” e “DeleteAll“).
Por exemplo, no nosso método “CarregarPessoasDoBanco“, nós não precisamos mais utilizar uma sentença SQL para pegarmos todos os registros da tabela “Pessoa” do banco. Basta utilizarmos o método “GetAll” do “Dapper.Contrib“:
// C# pessoas = conn.GetAll<Pessoa>();
' VB.NET Pessoas = Conn.GetAll(Of Pessoa)()
Além disso, no método “CadastrarPessoasNoBanco“, nós não precisamos mais construir uma sentença SQL para inserirmos uma nova pessoa no banco. Com o método “Insert” do “Dapper.Contrib” nós podemos passar a instância da classe “Pessoa” que deve ser inserida no banco e ele fará todo o trabalho por trás dos panos:
// C#
private static void CadastrarPessoaNoBanco(Pessoa pessoa)
{
using (var conn = new System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;"))
{
conn.Open();
if (conn.State == System.Data.ConnectionState.Open)
{
conn.Insert(pessoa);
}
}
}
' VB.NET
Private Sub CadastrarPessoaNoBanco(pessoa As Pessoa)
Using Conn = New System.Data.SQLite.SQLiteConnection("Data Source=db.db;Version=3;")
Conn.Open()
If Conn.State = System.Data.ConnectionState.Open Then
Conn.Insert(pessoa)
End If
End Using
End Sub
Porém, se executarmos esse novo código, nós receberemos o seguinte erro:
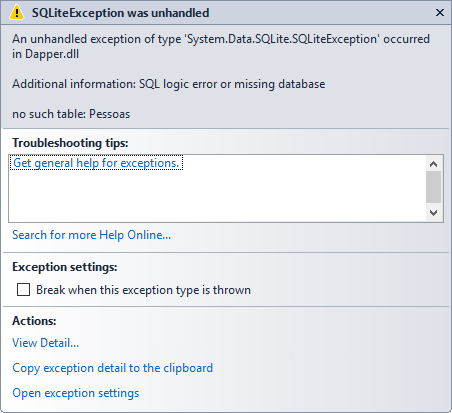
Esse erro ocorre porque o “Dapper.Contrib” considera por padrão que todas as tabelas estão pluralizadas. Ou seja, como a nossa classe se chama “Pessoa“, o “Dapper.Contrib” acha que as informações estarão armazenadas na tabela “Pessoas“, e isso não é verdade no nosso caso.
Nós temos duas opções para corrigirmos esse erro. A primeira opção é definirmos o nome da tabela na nossa classe “Pessoa” através de data annotations:
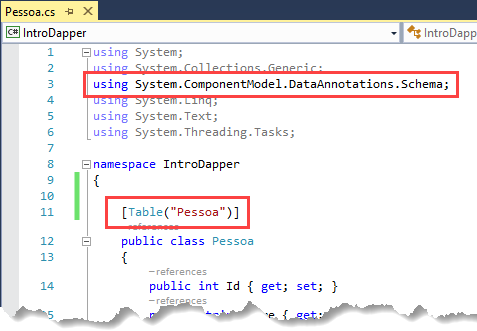
Porém, muita gente não gosta de poluir as classes de modelo com data annotations. Nesse caso, uma outra opção que temos à nossa disposição é a utilização do evento “SqlMapperExtensions.TableNameMapper“. Se colocarmos esse código no começo do nosso método “main“, o “Dapper.Contrib” considerará que as tabelas têm o mesmo nome das classes de modelo:
// C#
SqlMapperExtensions.TableNameMapper += (type) =>
{
return type.Name;
};
' VB.NET
SqlMapperExtensions.TableNameMapper = New SqlMapperExtensions.TableNameMapperDelegate(Function(type As Type)
Return type.Name
End Function)
E com esse ajuste o nosso projeto funcionará corretamente, salvando e carregando as informações da tabela “Pessoa“.
Operações mais avançadas
Como este artigo já está ficando muito longo, vou deixar algumas operações mais avançadas para outros artigos futuros. Veja aqui uma lista com possíveis temas para outros artigos sobre Dapper:
– Como carregar dados de mais de uma tabela ao mesmo tempo?
– Como trabalhar com relacionamentos entre tabelas?
– E se os campos da minha classe de dados não tiverem os mesmos nomes das colunas no banco?
Baixe o projeto de exemplo
Para baixar o projeto de exemplo desse artigo, assine a minha newsletter. Ao fazer isso, além de ter acesso ao projeto, você receberá um e-mail toda semana sobre o artigo publicado e ficará sabendo também em primeira mão sobre o artigo da próxima semana, além de receber dicas “bônus” que eu só compartilho por e-mail. Inscreva-se utilizando o formulário no final do artigo.
Concluindo
Micro-ORMs como o Dapper têm o objetivo de simplificar um pouco o processo maçante de leitura de dados quando trabalhamos com ADO.NET puro nos nossos projetos. Apesar de fazer o mapeamento objeto-relacional, ele procura manter as suas funcionalidades muito enxutas, a fim de não prejudicar muito a performance, ao contrário do que costumam fazer os ORMs “completos” como Entity Framework e NHibernate.
No artigo de hoje você viu uma introdução ao Dapper, onde você primeiramente aprendeu a instalá-lo e, em seguida, aprendeu a aplicar os seus métodos para simplificar os códigos de consulta e execução de sentenças SQL. Por fim, vimos a utilização de uma extensão do Dapper, chamada “Dapper.Contrib“, que implementa métodos que facilitam as operações de CRUD no nosso projeto.
E você, utiliza algum ORM nos seus projetos? Está contente com a sua performance ou está pensando em partir para um micro-ORM? Ou talvez você nem sabia da existência do Dapper ou nem sabia a fundo como o Dapper funcionava (como eu) e agora está pensando em utilizá-lo nos seus projetos também? Fico aguardando os seus comentários logo abaixo!
Até a próxima!
André Lima
Image by Pixabay used under Creative Commons
https://pixabay.com/en/network-rectangle-board-rings-1989141/
The post Introdução ao Dapper appeared first on André Alves de Lima.